Resum
| Tipus | Incident |
| Inici | 2024-06-07 05:14 (UTC) |
| Final | 2024-06-07 12:55 (UTC) |
| Tíquet | #1105 |
| Alertes | Sí |
| Reaccionen | @evilham, @exopedro, @dl.ramon, @jmoles, @dyangol, roger.garcia |
| Impacte | Algunes màquines virtuals (ambdós internes i de socis i clients) van estar no disponibles. Els serveis de connectivitat (Radio i Fibra òptica) i aquells considerats crítics es van mantenir. |
| Reporten | @evilham amb supervisió de @exopedro i @jmoles |
A causa de la migració de Datacenter a mitjans de 2023, la IPv4 del default gateway va canviar, i per tant els nodes del Clúster de Proxmox no tenien accés sortint a internet.
Això implica que el servei NTP (Network Time Protocol) no estava actiu i durant el temps els rellotges havien divergit (també hi ha un node amb pila BIOS exhaurida).
En un moment de càrrega (backup trax6) la comunicació entre nodes ha necessitat crear consens i això s’ha complicat per tenir les hores diferents; en aquest moment el trax7 ha activat el mecanisme de protecció i s’ha reiniciat.
Línia de temps

- 05:14 INICI INCIDÈNCIA
- 06:08 @evilham es connecta i intenta entrar via VPN
- 06:09 @evilham no pot fer servir l’VPN per actualitzacions de client OpenVPN; arregla la config
- 06:26 @evilham ja ha pogut entrar al clúster i va revisant UI proxmox + logs:
- Com a cosa interessant: hi ha algunes VMs que estan ensenyant 100% de CPU sense tenir aquesta activitat
- La màquina
tap265i0és d’una VM apagada que està esperant ser esborrada, és curiós que surti en els logs de backup - La tasca de backup falla justament amb la màquina
265. - El
dmesgen trax6 indica:
parts de dmesg
[32586406.568317] device tap265i0 entered promiscuous mode
[32586406.677217] gfs: dropped over-mtu packet: 4488 > 1500
[32586406.711049] gfs: dropped over-mtu packet: 9000 > 1500
[32586406.711463] gfs: dropped over-mtu packet: 7828 > 1500
[32586406.711829] gfs: dropped over-mtu packet: 8584 > 1500
[32586406.712132] gfs: dropped over-mtu packet: 4488 > 1500
[32586406.712163] gfs: dropped over-mtu packet: 8584 > 1500
[32586406.712502] gfs: dropped over-mtu packet: 9000 > 1500
[32586406.712718] gfs: dropped over-mtu packet: 4488 > 1500
[32586406.713075] gfs: dropped over-mtu packet: 9000 > 1500
[32586406.713251] gfs: dropped over-mtu packet: 4488 > 1500
[32586411.691117] net_ratelimit: 130 callbacks suppressed
[32586411.691119] pve: dropped over-mtu packet: 5724 > 1500
[32586411.693317] pve: dropped over-mtu packet: 5724 > 1500
[32586411.694839] pve: dropped over-mtu packet: 5724 > 1500
[32586411.696333] pve: dropped over-mtu packet: 5724 > 1500
[32586411.697555] pve: dropped over-mtu packet: 5724 > 1500
[32586411.698790] pve: dropped over-mtu packet: 5724 > 1500
[32586411.700284] pve: dropped over-mtu packet: 5724 > 1500
[32586411.701444] pve: dropped over-mtu packet: 5724 > 1500
[32586411.703031] pve: dropped over-mtu packet: 5724 > 1500
[32586411.704918] pve: dropped over-mtu packet: 5724 > 1500
[32586416.704869] net_ratelimit: 1678 callbacks suppressed
- 06:49 @evilham pausa una VM que ensenya un kernel panic en la interfície proxmox; també observa errors IO en alguna consola sèrie
- 06:53 @evilham intenta fer una migració “en calent” a trax7 d’alguna VM, això falla
- Apagar una VM (0.b3.eXO.cat) i migrar-la offline falla també
- 06:55 @evilham comenta que el kernel de FreeBSD està ocupant la CPU amb
CAMque vol dir “Common Access Method”, és la manera d’obrir block devices (IO) - 07:44 @dl.ramon demana comandes d’estat de cluster i @evilham les obté 10 mins després
estat cluster
[09:54:19] root@trax6:~# pvecm status
Cluster information
-------------------
Name: trax
Config Version: 17
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Sat Jun 8 09:54:25 2024
Quorum provider: corosync_votequorum
Nodes: 5
Node ID: 0x00000006
Ring ID: 3.63a
Quorate: Yes
Votequorum information
----------------------
Expected votes: 5
Highest expected: 5
Total votes: 5
Quorum: 3
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000003 1 192.168.96.13
0x00000005 1 192.168.96.15
0x00000006 1 192.168.96.16 (local)
0x00000007 1 192.168.96.17
0x00000008 1 192.168.96.18
[09:54:25] root@trax6:~# gluster pool list
UUID Hostname State
6b053145-78f1-4aaf-a2ba-348444253a0f gfs8 Connected
589e00b0-02b4-4740-90be-0ec98ee863db trax3 Connected
66a77469-9969-4fd6-85cf-9535b2f65d51 gfs7 Connected
3226a6f0-d48f-41a6-b8ae-ffd6ee751d6d gfs5 Connected
13a8bebf-c511-4314-8b0f-24cd2328623f localhost Connected
[09:54:29] root@trax6:~# gluster v status
Status of volume: media1
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick gfs5:/media1pool/brick1/media1 49158 0 Y 6555
Brick gfs6:/media1pool/brick1/media1 49158 0 Y 18052
Brick gfs7:/media1pool/bricka/media1 49152 0 Y 5108
Brick gfs8:/media1pool/brick1/media1 49158 0 Y 14616
Brick gfs5:/media1pool/brick2/media1 49159 0 Y 6574
Brick gfs6:/media1pool/bricka/media1 49159 0 Y 18072
Brick gfs7:/media1pool/brick1/media1 49153 0 Y 5115
Brick gfs8:/media1pool/brick2/media1 49159 0 Y 14634
Brick gfs5:/media1pool/bricka/media1 49160 0 Y 6592
Brick gfs6:/media1pool/brick2/media1 49160 0 Y 18093
Brick gfs7:/media1pool/brick2/media1 49154 0 Y 5122
Brick gfs8:/media1pool/bricka/media1 49160 0 Y 14652
Self-heal Daemon on localhost N/A N/A Y 5414
Self-heal Daemon on gfs5 N/A N/A Y 5037
Self-heal Daemon on gfs8 N/A N/A Y 5341
Self-heal Daemon on gfs7 N/A N/A Y 5207
Self-heal Daemon on trax3 N/A N/A Y 3037
Task Status of Volume media1
------------------------------------------------------------------------------
There are no active volume tasks
Status of volume: prova1121
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick gfs5:/vmpool/brick1/prova1121 49152 0 Y 5008
Brick gfs6:/vmpool/brick1/prova1121 49152 0 Y 5318
Brick gfs7:/vmpool/brick1/prova1121 49158 0 Y 5177
Brick gfs8:/vmpool/brick1/prova1121 49152 0 Y 5297
Brick gfs5:/vmpool/brick2/prova1121 49153 0 Y 5015
Brick gfs6:/vmpool/brick2/prova1121 49153 0 Y 5332
Brick gfs7:/vmpool/brick2/prova1121 49159 0 Y 5184
Brick gfs8:/vmpool/brick2/prova1121 49153 0 Y 5305
Brick gfs5:/vmpool/brick3/prova1121 49154 0 Y 5022
Brick gfs6:/vmpool/brick3/prova1121 49154 0 Y 5344
Brick gfs7:/vmpool/brick3/prova1121 49160 0 Y 5191
Brick gfs8:/vmpool/brick3/prova1121 49154 0 Y 5315
Self-heal Daemon on localhost N/A N/A Y 5414
Self-heal Daemon on gfs8 N/A N/A Y 5341
Self-heal Daemon on gfs5 N/A N/A Y 5037
Self-heal Daemon on gfs7 N/A N/A Y 5207
Self-heal Daemon on trax3 N/A N/A Y 3037
Task Status of Volume prova1121
------------------------------------------------------------------------------
There are no active volume tasks
Status of volume: vm_nvme
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick gfs5:/vmpool/brick1/vm_nvme 49155 0 Y 11219
Brick gfs6:/vmpool/brick1/vm_nvme 49155 0 Y 11477
Brick gfs7:/vmpool/brick1/vm_nvme 49155 0 Y 5140
Brick gfs8:/vmpool/brick1/vm_nvme 49155 0 Y 11396
Brick gfs5:/vmpool/brick2/vm_nvme 49156 0 Y 11242
Brick gfs6:/vmpool/brick2/vm_nvme 49156 0 Y 11495
Brick gfs7:/vmpool/brick2/vm_nvme 49156 0 Y 5149
Brick gfs8:/vmpool/brick2/vm_nvme 49156 0 Y 11414
Brick gfs5:/vmpool/brick3/vm_nvme 49157 0 Y 11260
Brick gfs6:/vmpool/brick3/vm_nvme 49157 0 Y 11513
Brick gfs7:/vmpool/brick3/vm_nvme 49157 0 Y 5158
Brick gfs8:/vmpool/brick3/vm_nvme 49157 0 Y 11432
Self-heal Daemon on localhost N/A N/A Y 5414
Self-heal Daemon on gfs7 N/A N/A Y 5207
Self-heal Daemon on gfs5 N/A N/A Y 5037
Self-heal Daemon on trax3 N/A N/A Y 3037
Self-heal Daemon on gfs8 N/A N/A Y 5341
Task Status of Volume vm_nvme
------------------------------------------------------------------------------
There are no active volume tasks
- 08:00 Coincidim que al cluster tot es veu OK, @evilham es desconnecta
- 09:00 @dl.ramon comenta: “Al fallar el node potser s’han quedat alguns vdisk en readonly i caldrà reiniciar les VMs”
- 09:21 @exopedro s’incorpora i comença a posar-se al dia
- 09:28 confirmem que no hi ha hagut cap actuació recent a DC ni en cluster
- 10:00 @evilham es torna a incorporar
- 11:04 Veiem que les hores no conicideixen al cluster
Hores en cluster
[2024-06-08 Sat 13:00:44] $ for host in exo-trax3 exo-trax5 exo-trax6 exo-trax7 exo-trax8; do ssh $host uptime; done
12:54:10 up 80 days, 18:45, 0 users, load average: 0.24, 0.12, 0.09
13:00:55 up 377 days, 9:54, 1 user, load average: 2.44, 2.48, 2.57
13:00:49 up 377 days, 9:54, 2 users, load average: 2.92, 3.20, 3.33
12:38:43 up 5:50, 2 users, load average: 1.02, 0.88, 0.60
13:00:54 up 377 days, 9:54, 4 users, load average: 5.29, 4.93, 4.50
- 11:04 roger.garcia ens confirma que podria haver causat l’incident, i que podem anar-ho arreglant
- 11:49 @dyangol ha donat accés a VPN via WireGuard a roger.garcia, que ja està disponible
- 11:50 - 12:50 sessió síncrona @exopedro, @evilham, roger.garcia:
- Tornem a revisar l’estat del cluster
- Revisem els logs per confirmar les hipòtesis
- Decidim que reiniciarem les VMs (amb stop + tornar a engegar) una a una
- Tornem a engegar les VMs que estaven apagades
- 12:55 FINAL INCIDÈNCIA
Detecció
status.exo.cat diu:
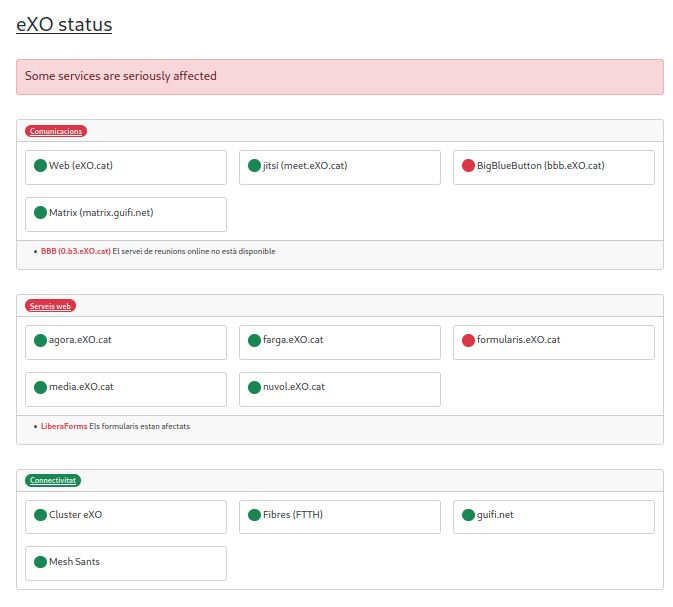
Les alertes són la primera cosa que veu @evilham en despertar-se i @exopedro en agafar l’ordinador.
També rebem notificació de @chris (admin de LiberaForms), que ha vist que el seu cluster de LiberaForms no funciona.
Possible millora d’alertes
- Els serveis web eXO.cat i nuvol.eXO.cat no han generat alerta, tot i estar lliurant un error 403
- Caldria revisar amb quins HTTP codes generem alertes
- La quantitat d’alertes era administrable i arribaven conjuntament
- Alertar quan les hores dels nodes no estiguin alineades
Conclusions
- Tot i ser una cosa que teníem marcada com prioritària en el procés d’actualització de cluster, no teníem present que pogués tenir una implicació tan greu que els nodes no tinguessin algun tipus de connectivitat sortint, com a mínim per NTP
- Hem de millorar la monitorització interna i externa del cluster, per tal que sigui accessible durant algun incident
Quà ha anat bé?
La monitorització amb status.eXO.cat ha anat molt bé i la comunicació amb @exo-servers ha sigut fluïda i constructiva.
Què no ha anat bé?
Tot i haver anat força bé, aniria bé tenir una guia de reacció a incidents.
En què hem tingut sort?
El pool media1 només te tolerància de fallo en 1 node (en NVMe de 2 nodes), el pool media1 no l’estem fent servir molt però hi hem de pensar si és acceptable i monitoritzar molt millor el cluster en general.
Hi ha hagut disponibilitat de diverses persones per comentar i revisar coses durant l’incident i hi hem pogut fer relleus.
Enllaços a documentació rellevant
- Ens hem inspirat molt fortament en la documentació pública de WMF’s Wikitech: Full response Template
Accionables
- Millorar monitorització externa de cluster
- Crear documentació de reacció d’incidents
- Revisar la redundància i tolerància a fallos de media1