Resum
| Tipus | Incident |
| Inici | 2026-06-17 12:26 (10:20 UTC) |
| Final | 2026-06-17 14:40 (13:00 UTC) |
| Tíquet | #1265 |
| Alertes | Sí |
| Participants | pedro, evilham, roger, víctor |
| Impacte | 50% aprox. de tots els serveis la majoria de temps de l’incident, tots els serveis en reestabliment servei |
| Reporten | @exopedro |
Situació espai disc redundat principal ha col·lapsat, algunes màquines han començat a deixar de funcionar, l’alliberament d’espai ha generat corrupció de dades en VMs que ha requerit reiniciar servei d’internet general
Línia de temps
Tots els temps en zona horària CEST.
- [ un altre queixa d’un servei de plataformess apunta a ahir per la tarda que un servei donava 502 bad gateway, i que podria estar relacionat, el fil de correu corresponent pedro el rep a les 12:22 ]
- 12:26 INICI incident
- 12:26 [ descobert a les 13:25 ] Segons una gràfica proxmox de media.exo.cat comença a fallar
- 13:16 leandro ens avisa que media.exo.cat no funciona
- 13:25 pedro reestableix aquest servei, però veu que afecta a altres serveis, i que és degut a problemes espai en vm_nvme, abaixa de 98.89% (4.08 TB of 4.13 TB) a 83.63% (3.45 TB of 4.13 TB). Alguns serveis han quedat una mica degradats o afectats, hi ha un problema general de connectivitat internet, i per tant relacionat amb els IX de sortida, i/o amb glutec.
- 13:49 pedro truca evilham, evilham diu que fibres funcionen
- 13:57 pedro truca roger garcia, roger garcia diu que no és problema general glutec, confirma per tant que és un problema d’eXO
- 14:00 pedro truca a víctor, i fem intervenció urgent de reestabliment ix. Reiniciem ix1, deixem ix2 apagat
- 14:40 FINAL incident ( status.exo.cat marca tot verd )
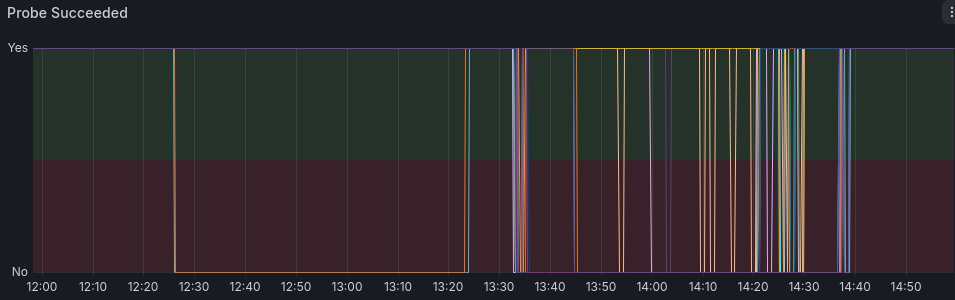
Detecció
Veure les diferents fases de detecció del problema explicades a través de la línia de temps
Possible millora d’alertes
- Afegir alerta storage proxmox de
vm_nvmequan està igual o per sobre de 80%
Conclusions
- Es confirma que el problema d’espai que veníem arrossegant pot arribar a ser bastant crític com hem comprovat
Què ha anat bé?
- La disponibilitat de l’equip per resoldre el problema ràpid, les eines com status.exo.cat, la interacció tant directa amb glutec
Què no ha anat bé?
- El volum d’alertes guifi.net ens ha generat un punt cec de les alertes que rebem; és bo que silenciem aquelles alertes que no som capaces de gestionar per tal de que arribin les importants
- Des de wireguard OOB és difícil gestionar proxmox
En què hem tingut sort?
- En haver-lo agafat a temps i no haver esperat gaire més
Accionables
- Silenciar alertes guifi.net (ens generen punt cec)
- Seguir abaixant ús espai en vm_nvme, ara està a 83.63% (3.45 TB of 4.13 TB) fins estar per sota de 80%
- Generar alerta si espai és igual o superior a 80%
- Idea: calcular espai total assignat a vm_nvme i que aquest no exedeixi 10% de l’espai total, evitant d’aquesta manera overbooking
- L’accés OOB no té accés a la VLAN 98
- Activar DNS autoritatiu extern (TODO evilham: documentar)